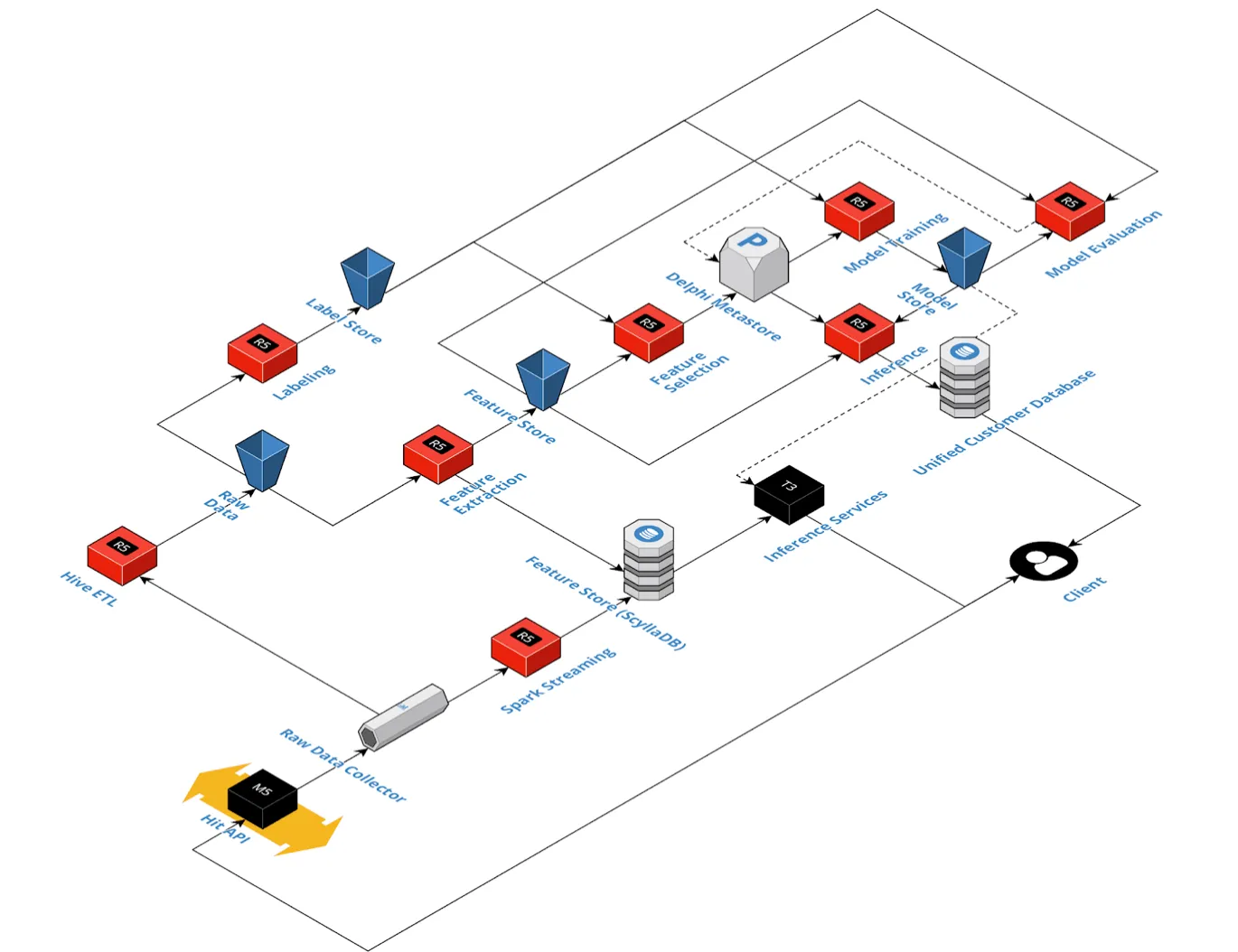
Insider uses Delphi, an auto-machine learning (ML) platform developed by Insider, to manage all of the ML workload.
Delphi handles every step of the ML pipeline. It maintains multiple feature stores of thousands of features that were built for different sorts of business problems. It populates these stores with historical and recent data on a daily basis. It trains unique models for each business problem per partner, totaling more than 2500 models per week.
Insider collaborates with a large number of partners from many countries and industry sectors. Users of an airline website in Asia will behave very differently from users of an ecommerce website in the US. Delphi accounts for these differences and makes us provide similarly precise predictions for all the brands we’re working with, regardless of their region and business vertical. Feature selection lies at the heart of what we achieve with Delphi.
This guide aims to answer the following questions:
- How does the feature selection work?
- What is Statistical Selection?
- What is Variant Selection?
- What is Feature Elimination?
- What is Recursive Selection?
How does the feature selection work?
The feature selection is handled by a single process for more than 10 algorithms that provide predictions for various business problems. The designs of these algorithms are significantly diverse. They feed from multiple feature sources and have various labels depending on whether they are numerical or categorical. Some of these are regression algorithms, and some of them are classification.
Statistical Selection
Starting with statistical selection, feature label pair tests are run. The next step is variant selection, where we choose from a feature’s different variations. What follows is feature elimination, where only one of the strongly correlated features survives. The final phase is recursive selection, where the so-far selected features are fed into a tree-based model in an iterative process.
The selection job requires an algorithm parameter to know which feature stores are used by the algorithm. There are multiple feature stores for various sorts of information. Suppose we want to predict whether a user will uninstall an application from their phone. In that case, we will refer to the Mobile Feature Store, where we have information regarding their device and their activities on the mobile platform. If we want to predict whether a user will open an email or not, then the information we need is stored in the Email Feature Store, where we store features related only to the users’ email habits.
With the algorithm parameter, the selection job knows which feature stores are suitable for that problem. This parameter also gives insight into the nature of the algorithm. For example, it can define if it is a regression or a classification problem, the minimum number of features we can accept at the end of this process, and if the importance scores we declare are too high or too low. Once the job knows this information, it creates a data frame of all the existing features from the suitable stores. The stores are built for general purposes, which is why not all features are relevant to every algorithm. In this case, we give them all to the feature selection job and let it decide.
During statistical selection, the job sorts available features and creates groups of feature-label pairs of various types.

When the label is categorical, the Anova test is applied for numerical features, and the ChiSquare test is chosen for categorical features. When the label and features are both numerical, we apply the Pearson test. Statistical selection is the lengthiest step of the entire process, that’s why we have added an option to skip to the variant selection when needed directly. This option is often used in the staging environment where we conduct experiments. In production, features get statistically selected first.
Variant Selection
Then, the variant selection becomes effective as our features have variations. For example, a single feature is computed for 4 data spans. If the feature is about the number of purchases a user makes, we aggregate that information for the past week, month, 3 months, and 6 months. We also store the square root, square, and natural logarithm of that information. This totals 16 variants for a single feature. To ensure the final model receives the best variant, we obtain feature importance from a tree-based model and proceed with the variants that have the highest importance.
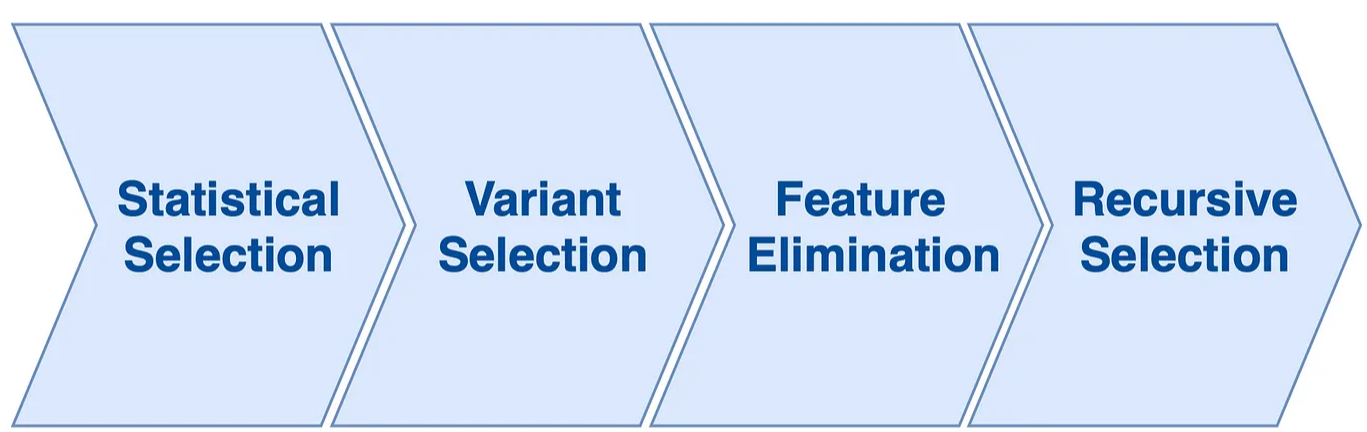
Feature Elimination
Before the last step, there is a feature elimination process based on feature-feature correlations. If two features are highly correlated with each other, only one of them makes it to the final model. To decide on which features to eliminate, two correlation matrices are created: one for categorical and one for numerical features. If the correlation between these features exceeds the determined elimination threshold, the feature with the highest correlation to the label is retained.
All available features are subjected to statistical tests against the label. As the resulting features can be of different variations of data spans or orders, the best variant of every feature is selected in a variant selection step. The features resulting from this stage may be highly correlated with each other, so the feature elimination step takes care of that and picks the best features in highly correlated pairs.
Recursive Selection
The final stage is recursive selection. Here, we train a tree-based model that is fed with the selected features. The model is then evaluated. Features that fall below a specific importance score are removed, and another model is trained with the remainder. This process is repeated for the desired number of times. In the end, scores from each iteration are looked at, and the model with the best evaluation score decides the final features.
Thousands of features get calculated by our auto ML platform every day. Not all of them are relevant to every algorithm we create to solve business problems. We also train a unique model for each of our customers, and their users have varying behaviors depending on the region and industry. This poses a challenge in selecting the relevant features for each model because creating features that are relevant to the problem and choosing them is crucial for training a high-quality machine learning model. Our feature selection process begins with over 2000 potentially relevant features, which can be eliminated until only a dozen remain.